![golang: clean architecture in projects [video]](https://2581766.fs1.hubspotusercontent-na1.net/hub/2581766/hubfs/Golang-cover2-min.jpeg?width=1320&name=Golang-cover2-min.jpeg)
I am sure that every developer (at least once) has to work in unsystematic code files. There is nothing more annoying. Today, I want to show you how organizing application code can improve your work. During years of my career, I had opportunities to implement a Clean Architecture approach in projects. In my opinion, it works very well, and it is worth using.
There are many reasons why we should keep the specific structure. First of all, it is much easier to search, debug, and enhance the code. Keep in mind that the project will probably grow in size, and the team has to be able to implement the changes quickly. Speaking about teams, most of us are cooperating with colleagues in daily work - this also happens in the Railwaymen software house where I work. In that case, the code organization is significant. It is much more comfortable to manage and maintain the organized code structure. I strongly advise you to practice this as a habit.
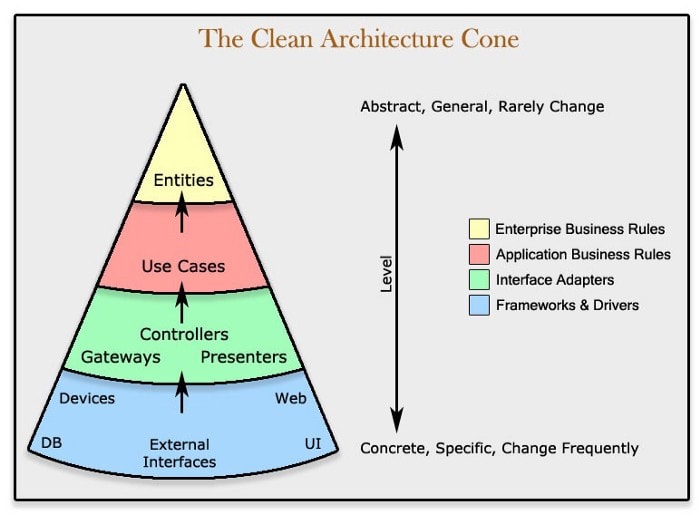
Table of Contents:
1. Main layers of the architecture.
2. General benefits of clean architecture.
Main layers of the architecture
Entities
- Represent your domain object e.g. User, Game Level
- Apply only logic that is applicable in general to the whole entity (e.g., validating the format of a user’s email)
- Implemented as plain objects with no frameworks and external dependencies
Entities are the heart of clean architecture and contain any business rules and logic. The goal is that they contain principles that are not application specific — so basically any global or shareable logic that could be reused in other applications should be encapsulated in an entity, e.g. the user has to have an email address.
An entity is a set of related business rules that are critical to the function of the application. In an object oriented programming language the rules for an entity would be grouped together as methods in a class. The entities know nothing of the other layers. They don’t depend on anything. That is, they don’t use the names of any other classes or components that are in the outer layers. Here is an example structure of User.
package models
type User struct {
ID int64 `json:"id"`
shopify_ID string `json:"shopyfi_id"`
Name string `json:"name"`
Score int `json:"score"`
Email string `json:"email"`
Tags []string `json:"tags"`}
func (u *User) GetShopifyID() int64 {
return u.shopify_ID
}
Use Cases
Moving up from the entities we have the Use Case layer. The classes that live here have a few unique features and responsibilities:
- Represent your business actions: it’s what your application can do. Expect one use case for each business action
- Pure business logic, plain code (except maybe some utils libraries)
- The use case doesn’t know who triggered it and how the results are going to be presented (for example, user synchronization, adding tags for users)
package usecase import ( "./shopify-game-player/player/models"
"./shopify-game-player/player/repository"
)
type UserUsecase struct {
userRepo repository.UserRepo
userShopifyRepo repository.UserShopify
}
func NewUserUseCase(userRepo repository.UserRepo,
userShopifyRepo repository.UserShopify)
*UserUsecase {
return &UserUsecase{
userRepo: userRepo,
userShopifyRepo: userShopifyRepo,
}
}
func (userUseCase *UserUsecase) FetchUsers(userCount int) []models.User {
return userUseCase.userShopifyRepo.Fetch(userCount)
}
func (userUseCase *UserUsecase) AddTagsToShopifyUsers(userID string, tags string) models.User {
return userUseCase.userShopifyRepo.AddTags(userID, tags)
}
Data provider
- Retrieve and store data from and to a number of sources (database, network devices, file system)
- Implement the interfaces defined by the use case
- we can use framework to connect to database
For database interactions it is recommended to use the Repository Pattern which encapsulates all your database interactions through an abstraction layer. The repository pattern does give you a bit freedom to replace databases with ease.
//UserRepo struct for handling db
type UserRepo struct { DB *sql.DB}
// NewMysqlUserRepository will create an implementation of user.Repository
func NewMysqlUserRepository(db *sql.DB) *UserRepo {
return &UserRepo{ DB: db, }
}
//FindAll use for find all uses
func (repo *UserRepo) FindAll() (*[]models.User, error) {
results, err := repo.DB.Query("SELECT * FROM users")
if err != nil {
panic(err.Error())
}
defer results.Close()
var user models.User
var users []models.User
for results.Next() {
err = results.Scan(&user.ID, &user.Name, &user.Score, &user.Shopify_ID)
if err != nil {
panic(err.Error())
}
users = append(users, user) }
return &users, err
}
Interfaces / Adapters
- Implement the interfaces defined by the use case
- There are ways to interact with the application, and typically involve a delivery mechanism (for example, REST APIs, scheduled jobs, GUI, other systems)
General benefits of clean architecture:
- Independent of framework
- Independent of UI
- Independent of Database and Frameworks. The software is not dependent on an ORM or Database. You can change them easily.
- Testable. Now it is intrinsically testable. You can test business rules without considering UI, Database, Mock servers, etc.
As you can see, we have to remember several general rules while focusing on clean architecture. Watch the video (ENG subtitles are available in the options) and gain knowledge about this approach 👇

And if you want to know more about our web development services and how we use Go and other programming languages to create apps of an awesome quality - check the place below!
Railwaymen Web Development Services
.png)



![why use golang to build your business app in 2025? [6 benefits]](https://2581766.fs1.hubspotusercontent-na1.net/hub/2581766/hubfs/golang-cover-min.png?width=1905&height=510&name=golang-cover-min.png)